スパコン”京”の世界一位の危うさ. スパコン開発の進路はスピードからスマートへ
- 技術と科学の区別を意識して論じよう -1
2011年07月10日記述
ひと悶着あったスパコン”京”が、この春のTOP500スパコン・ランキングでブッチギリの一位に輝きました。そのインパクトは多大ですが、一方で米国では、オバマ大統領の科学技術アドバイザリーボードである
PCAST(President’s Council of Advisors on Science and Technology) が、昨年12月に、TOP500のスパコン・スピード競争への過度なのめり込みに対して強い警告を発しています。
このような環境で現在開発中なのがIBM Blue Water ですが、比較なども交えて、辛口の論考を行います。
(追記(11/16/2011): その後 IBM Blue Water がキャンセルされてしまいました。それも踏まえて、小生の主張は変わっていません。お時間があれば、ラマンチャ通信TOPから、その後のブログも参照頂ければと思います。)
”一位”が持つブランド力、効果・価値は、やはり凄い.しかし話しが出来すぎていないか
スパコン”京”が、TOP500スパコン・ランキングの一位に輝きました。
東北大震災の未曽有の爪痕の惨さと、未だ一向に先が見えない福島原発処理に起因する、節電一方の暗い世相の中で、パっと閃いた一条の強い閃光として、我々日本人に強烈な印象をもたらしました。
殆ど喪失しかけていた日本人の技術力に対する自信を、一気に回復させるほどのインパクトです。
昨年の秋のランキングで、中国が一位に彗星の如く顕われたショックからも、正直、回復できる思いです。
”一位”が持つブランド力、効果・価値は、やはり凄い。
ということで、この”京”開発国家プロジェクトに色々と疑問符を投げかけてきていた小生も、すっかりミーハー族に成り果ててしまっていたのです。
事業仕訳での蓮訪さんの発言、 「2位じゃダメなんですか?」 、が嘲笑の対象になってしまいました。
当時舌鋒鋭かった池田信夫さんや能澤徹さん達も口を閉ざしているように見えます。
ところが、先日、さる高名なIT業界ジャーナリストであるAさんから、”これどう思う?”、という鋭い質問のパンチを喰らってしまいました。
暗い世相に飽き飽きし、素直にこの成果を喜んでいた大甘な小生は、即座には、”これでいいじゃない”、という皮相的な反応しかありませんでした。
しかし、そのうちに、Aさんの、本物のジャーナリズムの姿勢の厳しさに舌を巻く思いが強くなりました。
今は、さすがプロは違う、と感じ入っています。
じっくり考えていると、どうも産官学連携の罠に嵌まっているような気がしてきました。
ちょっと話しが出来すぎていないか。
小生は今、このプロジェクトはやっぱり、少しいかがわしいのではないか、という疑惑に悩まされています。
そして、IT 世界の技術競争で、スピードからスマートさに大きく進路変更が起きている今、この京の大成功で、なお一層日本のITが、大鑑巨砲主義の、時代遅れの道にのめり込んでしまうのではないか、という懸念が、小生の頭の中でより一層強くなっています。
世相が、あれも悪いこれも悪いの足の引っ張り合いの知のデフレ・スパイラルに陥っている時に、できるだけポジティブな評価を、とは思います。 しかし、嫌われもするでしょうが、しょうがありません。
”京”.貴職は白馬の騎士?それとも”科学技術”が枕詞の”振り込め詐欺集団”?
確かに富士通の技術力が世界で見直されています。これは喜ばしいことだと思います。
この大きな成果は、本物の実力と、技術者の物狂いに似た献身的な努力の結果であると思います。
富士通の技術者魂の、負けず根性、継続する力に負うところが大きいのでしょう。
暗い世相に突然飛び出してきて悪を粉砕する、白馬の騎士のような美しさ、ロマンがあります。
しかし、これが危うい。
過去には何回も、誇りが驕りに変質していった情景を見てきました。
しかも、今回の風景には復古調、レトロな色合い、セピア色の空気が漂っています。
”京”の産官学連携の当事者が強く反発する、”大鑑巨砲主義”、の隠し味というか、それが色濃く出ている。
戦艦大和、されど戦艦大和です。幻の宇宙戦艦ヤマトでも創ろうとしているのでしょうか。
小生が抱くいくつかの疑問点を、想起するままに以下に書き上げます。
昨年の中国が一位、今回の日本が一位と、アジア勢が頑張っているように見えますが、何の競争なのか。
TOP500というスパコンの世界一位競争とは、内容的には何の競争なのか。
結果として一位となったときに、新興国と伍した国威高揚競争で、得られるものは何か。
”京”は1000億円以上の税金を、”科学技術”村社会の研究者達に配るための、集金マシーンではないのか。
もしそうなら、この成功を受けて、次世代のExascale computingではさらに莫大な集金マシーンの開発が始まるのではないか。
仮に、産官学連携のボスがいて、学問評価やポスト、さらには金の流れなど、現世利益をコントロールする利権構造があるとしたら、一部の土木建築業界と同じように、日本国を蝕む、構造改革すべき対象でしよう。
それが、”科学技術”という錦の御旗を堂々と押し立てている点で、さらに危うい思いです。
今、日本国、日本民族が襲われている原発の悲劇に至った体質と、大きくオーバーラップしてきます。
さて、今回のTOP500の結果を受けて急遽行われたTOP500主催者側のテレコンを、Webで聞きました。
今回の”京”の結果については、”チョット信じられないよね”、という相当ハイレベルの評価でした。
とにかく凄いよね、と。amazing だと。
”あの富士通が帰ってきたよ”、というのは、30年程前に、LINPAKベンチマークの開発と普及で日本のスパコン業界で名を売っていたJack Dongarraさんです。今でもTOP500の黒幕のような存在です。
Gene Amdahlのアーキテクチャと技術力を手にした当時の富士通は、ライバルのIBMが真っ青になる程、技術計算に強いメーカーになっていました。スパコンのVPシリーズは名機でしたね。
また、NECの技術も凄かった。日立も凄かった。
半導体で世界を制覇したのと同様に、スパコンの世界でもCrayを押しのけ、日本勢の独壇場だった。
今と大きく違うのは、アセンブラー・チューンのCrayに対して、Ken Kennedy 教授肝いりの、ベクターオプティマイズドなFORTRANコンパイラーという、ソフトウェアのイノベーションを世界に発信していました。
”地球シミュレータの渡辺さんが、NECから富士通に移って作ったんだよ”(?)。
”28時間も稼働したそうだ”、”93%の効率なんて信じられないよね”、”6次元のトーラスネットなんだ”、
”SPARC/Linuxだって”、”熱効率も凄いんだ”、
との、賛辞とも驚愕ともとれる会話が、TOP500の新旧の当事者間で飛び交っていました。
これって、凄いです。しかし小生の耳には、スパコン・オタッキーの、サブカルチャーの饗宴のような響きだけが残りました。
Jack Dongarraさんが前置きで、TOP500は(自分が創った)LINPAKだけの競争だから、スパコンの能力を評価しているわけではないよね、と、当事者特有の巧妙なディスクレーマーで煙幕を張っていましたが、しかし全くその通りだと思います。
そのJack Dongarraさん達の会話のベースは、ディスクレーマーはそれとして、技術のトンガリだけを面白がっている風情を、強く滲ませていました。
実際に、8.126 Pflops をたたき出した技術力は驚異的です。
しかし、しかしですが、冷静に考えると、これって何かおかしいことに気づきます。
巨大なマシーン・ルーム一杯に展開された672筐体(CPU数68,544個、コア数548,352)の巨大システムが、
93%の実効効率で28時間実稼働したなんて、マジックに見えます。そう、奇術のようです。
(93 per cent computational efficiency (Linpak RMax/RPeak)) .
理論値の93%で連続稼働ですよ。
そしてまた、あんなに大騒ぎしてNECと日立が降りたベクター型主システムを欠いて、仕訳騒動でスケジュール的にも大きなハンディを負った筈の”京”が簡単に世界一位になってしまった。
でも、これって、マジックでも何でもありません。
これは、”京”が徹底的にLINPAKに適合したマシンである事を逆にゲロしているようなものです。
勿論、それ相応の卓越した技術力がなければ達成はできませんが。
”京”はTOP500世界一位を狙ったLINPAKチューンのピーキーか?
こういうのを自動車業界ではピーキーと呼ぶらしい。
ある特定の回転域の部分だけ極端にハイパワーが発生するエンジンをピーキーと呼ぶのだそうです。
その他の回転域では「ほとんどパワーらしいパワー」がでないのでこう呼ぶらしい。
この場合には、このピークはLINPAKで代表される密係数行列計算です。
尤も、LINPAKは伝統あるベンチマーク・テストであり、いかがわしいということではありません。
また、”京”が非常に狭い範囲の応用計算にしか向いていない、などと言っているわけでもありません。
云いたいのは、人間の幅広い知の冒険の力量を量るには、相当狭く偏っている、ということです。
ウイキペディアを引用すれば、
「LINPACK ベンチマークは、LINPACK に基づいたベンチマークプログラムである。理学・工学で一般的な線型方程式系(大きさは自由)をガウスの消去法で解く速度を測定し、システムの浮動小数点演算性能を評価する。ただし密係数行列。一般に、差分法や有限要素法などで解かれる大規模問題は、連結リストによって記述される参照の局所性の低い疎行列系であり、キャッシュメモリの恩恵をほとんど受けない。(つまりメモリバンド幅によって性能が決まる。)したがって、必ずしも実アプリケーションの性能を示すものではなく、指標の一つとして考えるのが妥当であろう。」
また、あるブログに、LINPACKの如何にもチューンし易い端的な特徴の記述がありました。
「Linpackは、キャッシュが大きければ主記憶バンド幅は狭くていい。
主記憶が大きければネットワークバンド幅は狭くていい。
L1が大きければL2のバンド幅は狭くていい。
レジスタが沢山あればL1は狭くていい。
といったメモリの階層性を有効利用可能なベンチマークである。」
さて、”京”の全ては富士通の技術で構成され、プロセッサの命令アーキテクチャもSPARCベースです。
しかしJack Dongarraさんも指摘するように、ISA(Instruction Set Archiecture)のベースがSPARCというだけで、
”京”の性能を叩き出しているのは、プロセッサー(SPARC64 VIII fx)が、HPC向けに大幅に命令拡張、レジスター拡張、コア同期拡張などが行われていることによります。
HPC-ACE(High Performance Computing - Arithmetic Computational Extensions)」という名の、SPARCの標準から大きくHPC(High Performance Computing)に偏向・強化した、新しいアーキテクチャだと云えます。
これは、プログラマーが積極的に利活用できるという点で、隠れたハードウェア実装であるマイクロアーキテクチャの強化とは一線を画すものです。
SPARC64 VIII fxでは、従来のSPARC64プロセッサの浮動小数点レジスタが32個であったのを、一挙に256個に拡張し、整数レジスタについても拡張グローバルレジスタを32個追加し、従来のウィンドウレジスタと合わせて64個に拡張しています。
さらにキャッシュの構造もループ処理に適合できる構造で、LINPACKのような密係数行列演算で、メモリー・ハイアラキーの効果を最大限に発揮できる構成になっています。
例えば、HPCとしてループ・モードにも適応出来るキャッシュ構造は、規則的なデータの流れを支援し、書き換えで乱れるバス実行性能を4倍近く高めるといわれます。
処理系としての転送のオーバヘッドが大幅に減って、懸案の大規模CPU連結負荷が大幅に軽減されます。
LINPACKの計算中はI/O動作は不要なので、データ系が乱れる心配もない。
SPARC64 VIII fxは8コア/チップですが、8コアでの並列処理の効果を引き出すために、ハードウェアバリアという機構を装備し、チップあたりのループ処理などの、粒度の小さい並列処理オーバーヘッドを大幅に下げる機構が設けられています。
逆にSPARC64 VIIで採用していた汎用のマルチスレッド構造は、邪魔なだけなので落とされています。
これは後述するIBM Blue Wartersの汎用POWER7採用の思想とは全く違ったアプローチになっています。
Blue Wartersの設計思想は、出来るだけ幅広い応用分野のプログラミング容易さを満足するスパコン作りを目的としているため、POWERアーキテクチャに手を加えてはいません。
例えば、アーキテクチャ上の浮動小数点レジスタも32個のままです。
勿論、HPCの性能を追求する上で、数々の新しいマイクロアーキテクチャは実装されています。
例えば、eDRAMによるオンチップL3キャッシュは32MBもあり、4マルチスレッド(SMT)も実装しています。
重要なのは、技術計算だけでなく、データベース処理やクラウド時代でより重要になる、TLP(Thread Level Processing)などの多様な処理形態に、プロセッサー自身が動的に適応できる構造になっている点です。
また、強烈な仮想化機構も実装しています。これは浮動小数点演算とは何も関係がありません。
この汎用プロセッサーをBlue Wartersは選択した。
SPARC64 VIII fxではL2キャッシュは5MBしか実装されていませんが、256個の浮動小数点レジスタや
ループ処理に適合したキャッシュの構造などで、高い浮動小数点演算能力を叩き出しています。
また、汎用のTLP処理なども視界にあるPOWER7のCPUクロックが4GHzという高速で、発熱も200Wという高いレベルに対して、SPARC64
VIII fxは2.2GHzで58Wと、”京”の熱効率に大きく貢献しています。
LINPAKのような浮動小数点演算性能を上げるだけなら、熱効率上、低クロックの方が適しているのは、IBM のもう一つのスパコン路線である、Blue Gene/L,P,Qの実績でも明らかです。
チップ当たりの浮動小数点演算は、POWER7が256GFlops、SPARC64 VIII fxが128GFlopsです。
いずれにしても、HPC-ACEは伝統的な技術計算性能向上に関して、様々なチューニングがなされているわけです。SPARC汎用プロセッサーというよりは、富士通の長いスパコン開発のノウハウを結集した、プロプライエタリーな、技術計算用の特殊プロセッサーと考えるべきものでしょう。
事実、SPARCプロセッサーの汎用コンピュータ・ビジネス展開で提携する富士通とOracleは、このSPARC64 VIII fxが、次期SPARCプロセッサーでどのような位置にあるのかどうか、全く言及していません。
海外のジャーナリストは、SPARCサーバー拡販のためにも何故喧伝しないのか、訝しがっています。
何か政治的な背景あって言えないのかもしれませんが、特異なプロセッサーであるのは事実でしょう。
PCASTの警告.米国のスパコン開発の進路は、スピードからスマートへ
”京”のことを”ピーキー”と決めつけ、”産官学連携の集金マシーン”ではないか、という小生の文章は、少々辛辣に過ぎたかもしれません。
世界一位のニュースに小躍りした自分が恥ずかしくって、精神のリバウンドが強すぎたようにも思います。
しかし、最近の日経の記事などを見ても、文化省や理化学研究所が防災分野への利用を声高に取り上げるなど、どうもこのプロジェクトは順番がオカシイ。
例えば、富士テレビの番組のオープニングで、小倉さんが紹介していた話も変です。
”京”を企業に貸し出します、という話で、 スパコンを使いましたと公表してくれれば使用料はただ、公表しないと3日で1000万円かかる、ということらしい。
1000万円の根拠は、小倉さんによると電気代。1年間に12億円だということです。
結局、”京”は使い道が元々不明で、利用者側のニーズから開発された代物では無いということでしょう。
こう云うと、今までのスパコンの能力では不可能だった科学技術計算の世界が大きく切り開かれるのだ!、
シミュレーションの回数が桁違いになるのだ!、という絶叫が返ってきます。
小生は算法の専門家ではないので大きなことは言えませんが、実世界の計算量Oのオーダーは、”京”ぐらいのスピードアップではキャッチアップ出来ないのではないか。
だからこそ、アメリカ国防総省の国防高等研究計画局(DARPA)が言い出したExtreme Scale Computing、
UHPC(Ubiquitous High Performance Computing )のビジョンに右往左往しているのではないか。
だから、今利活用されているアプリケーションを、改めて”京”に移植する逼迫した緊張感はないわけです。
時代のニーズに時間的にずれてしまった大鑑巨砲主義の、数年後の侘しい風景も、垣間見えます。
というのは、世界のスパコン業界の流れの一つが、今回の”京”のような伝統的なCPU一辺倒から、アクセラレータと呼ぶ専用プロセッサーとのハイブリッド構成へと大きく流れが変化してきていることにあります。
何しろ、アクセラレータはワークロード(応用プログラム)とマッチすれば、CPU(汎用プロセッサー)の100倍i以上の性能をたたき出すことが可能なのです。
その典型が昨今のGPGPUとコモディティなx86 CPUとを組み合わせたスパコンの勃興です。
(GPGPU: General-purpose computing on graphics processing units)
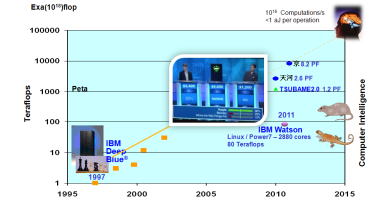
昨年秋の世界一位に躍り出た中国の天河がこの方式です。
日本でも東工大の松岡教授のTSUBAME 2.0が、昨年4位、今回5位とTOP500上位に食い込んでいます。
高価なプロプライエタリなCPUを開発するよりも、ほぼ誰でもが、大量生産で安価になったコモディティの技術を利活用できるわけです。そして計算の熱エネルギー量も大きく低減されます。
CUDAというソフトウェア開発プラットフォームが整備されつつあり、ユーザーが集まりつつあります。
CPU(汎用プロセッサー)とアクセラレータの組み合わせは、GPGPUに先行して、CRAYアーキテクチャのベースにもなり、IBM RoadrunnerがCellとAMD(x86)の組み合わせで、TOP500で初めてPetaFlopsの壁を破りました。
そんな技術の流れの中で、SPARCというCPU(汎用系マイクロプロセッサー)だけで構成される”京”の構成は、世界のHPCの世界ではかなり大きな違和感で受け取められているようです。
二つ目の世界の流れはより重要で、スピードからスマートへの技術の大きなうねりです。
GPGPUなどによる安価なスパコンのスピード競争は、反面、応用プログラムの作り難さ、困難さをより顕在化させています。
TOP500のLINPAKのような、ベンチマークプログラムによるレースカー競争の虚しさが、益々明確になってきているわけです。
プログラムの開発が困難ではその作業に忙殺されてしまい、科学者の自由な知の冒険もままなりません。
そういう科学者の憤懣が一気に顕在化したのが"work smarter, not faster"の要件です。
Smarter Not Faster: Supercomputing Race Changes Course
Supercomputers Let Up on Speed
このスパコン進路変更の支持者が米国では増えているように見えます。
事実、オバマ大統領の科学技術アドバイザリーボードである PCAST(President’s Council of Advisors on Science and Technology) が、昨年12月に、TOP500のスパコン・スピード競争への過度なのめり込みに対して強い警告を発しています。
腕力だけのスピード競争が、価値ある科学への努力を蹴散らかしているという、危機感があります。
腕力に頼るスピード競争に嵌まっていると、ろくでもないソフトウェアしか出来上がってこない。
(今回のTOP500で、IBMが上位から姿を消してしまっているのは、この警告と関係あるのかもしれません。)
このような"work smarter, not faster"の代表が、”京”の最大のライバルであるBlue Watersです。
Blue Watersは、米University of Illinois, Urbana-Champaignと、同大学にある米国立スーパーコンピュータ応用研究所(NCSA:National
Center for SupercomputingApplications)、IBM、Great Lakes Consortium for Petascale
Computationが共同で開発しています。
プロセッサーには前述したIBM POWER7が使用されており、DARPAの前回のRFPでもある、PERCS (Productive, Easy-to-use, Reliable Computing System)を継承した構成です。
特徴的なのは、ソフトウェア開発の容易さとデータ処理能力への傾注です。
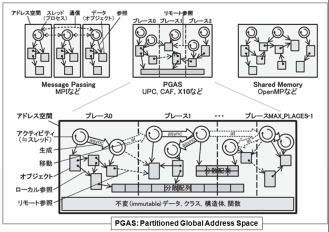
ザックリといえば、並列処理における部分共有メモリー空間と、20PBの外部データとの一体処理です。
その意味では、浮動小数点演算性能追求一本の”京”とは大きく違った設計思想で開発されています。
Blue Watersは、InfinibandやIBMの独自設計のSysplexから発展したオープンのRDMA (Remote Data Memory Access)などを組み合わせた、新世代のインターコネクトを採用しています。
IBMではPOWER4からマルチコアやチップ搭載メモリー・コントローラーなど、完全分散のプロセッサー結合を進めていましたが、ベアなPOWER7では256コア1対1直結が可能で、同時に20,000データ・ハンドリングのリオーダー整合性処理が可能です。
PERCSでは4個のPOWER7に1個のハブチップが付いてモジュールを構成、メモリーはコア直結ですが、系全体のクラスター、PCIe、ネットワークというインターコネクトを実行し、合計1128Gバイト/秒のピーク帯域幅を、各ノードやスーパーノード、汎用入出力タスクなどに振り分けるのだそうです。
これが、あの、バカデカくって、悪名高き”畳”の正体ですが、浮動小数点演算性能追求の”京”のTOFUのトーラスとは、データセンタを畳に集約したようなデータ処理系という点で、比較の対象ではありません。
畳のプリント基板は日立が分担しているとのことですね。
ソフトウェア・アドレス空間も、並列処理のプログラミングを容易にするPGAS(Partitioned Global Address Space)型のアーキテクチャを開発し、新しくX10というJava拡張の並列型言語を、既にオープンソース化しています。この構造は、人間の脳の記憶モデルを参照しているという指摘もあります。
従来の単純なクラスター型分散メモリーではありません。
Jack Dongarraさんによると、Blue Watersは現在、設計面で遅延が起こっているのだそうですが、この構想の壮大さからすると、さもありなんだと思います。
来年春のTOP500には間に合わないのかもしれません。
一方で、このIBM POWER7を2880 コア搭載したサーバー、IBM Watson という曖昧質問の解析マシーンが、Jeopardy という米国の人気クイズ番組で人間のチャンピオンに挑戦してこれを打ち負かし、賞金王になりました。
このマシーンは高々80 Teraflopsの浮動小数点演算性能しかなく、とてもTOP500のスパコン・ランキングにも登場しないのですが、全米の大きな話題になりました。
IBM Watsonは、計算スピードでは遥かに劣るものの、コンピュータのインテリジェンスでは歴史的な能力を発揮したのです。
人間の脳の情報処理能力は、1016Computations/s < 1 aJ per operation だそうです。コンピュータ・ロジックの消費電力が1 aJ を切るのが2020年頃になりそうなので、このころ何かが起こるのかもしれません。
その他にもIBMは、Wire-speed Processorという呼称で、アクセラレータとして位置づけられたりしていたPOWERのメニーコア・チップ(Prism)で、ネットワークに配置された分散コンピューティングのモデル構築をやっているやに伝えられています。
チップ上のコア間信号伝送に必要なエネルギーは10pJ/Byte、チップ間が100pJ/Byte、メモリは1.5nJ/Byteを必要とする、ということなので、分散データに処理系を配置するストリーム処理は、新しいNon
Von Neumann Architectures の計算機系モデルの一つとしても期待されます。
低消費電力の課題解決は、GPGPUによるチャレンジとは別に、ARMやATOMというMicroserver プロセッサーの活躍が期待されていますが、PowerPC
440系をHPC用にチューンしたBlue Gene/Qの動きも気になるところです。
さて、小生が考えるスピードからスマートへの技術の流れは、伝統的なHPCの世界を超えて、今IT業界の大きな筋目を作っている、クラウドのビッグデータ処理であり、モバイルやAR(Augmented Reality)であり、そしてスマート・プラネットを支えるストリーム・コンピューティングです。
これらの処理系は、2008年に米国科学財団(NSF)がCPS(Cyber Physical System) として打ち上げた新しい旗のもと、ITによる人間の幸福やより洗練された物理世界を目標にして、直接的で革命的な挑戦と貢献の研究・開発が始まっています。
これが、DARPA提唱のUHPCと合流して、新次元スケールの情報処理世界へと変貌していくのでしょう。
ここで競われるのは、単なるLINPAKのような不動小数点演算のスピード競争ではなく、コンピュータのインテリジェンスを如何に引き出し、如何に多様な未来形のアプリケーションを迅速に創り上げられるか、です。
まさに実ビジネスと社会貢献の価値創造での、科学者の知のスマートさの競争が始まっているのです。
このような曙に、”京”という数十年来のLinkpakに特化したスパコン仕様が、どのような明日をもたらすのか。
富士通の間塚会長は、2015年度にはHPC関連の売り上げを現行の5倍にあたる1000億円まで伸ばし、あわよくば米IBM並みの30%の世界シェアを狙いたいと云っています。
それが達成されれば良くも悪くも、大鑑巨砲主義の負の効果も出てしまっているのかもしれません。
小生が最も心配するのは、”京”の成功(?)で産官学連携の旧弊の構造が”科学技術”の枕詞のもとでさらに跋扈し、既に順調にスタートしているやに見える喜連川東大教授達のCPS絡みの努力をスポイルし、失速させてしまうのではないか、という危うさです。
哲学への憧憬:福島原発に見る科学の堕落と技術の堕落.知の発現としての美・善・真
-技術と科学の区別を意識して論じよう -2
に続きます。
↑
|