IBMがNCSAへのスパコンBlue Watersの納入をギブアップ ! さて京の戦略は?
2011年08月09日記述
2011年8月8日のIBM NCSAの共同プレス発表によると、IBMがイリノイ大学へのBlue Waters 納入契約を打ち切ったということです。
理由は、予想以上の複雑さとコスト増で、当初予算では完成できないということのようです。
IBMはこれまでに受け取った資金を返還し、NCSAは一部納入された機器を返還するらしい。
契約額は総額約2億800万ドル程度らしい。
"The innovative technology that IBM ultimately developed was more
complex and required significantly increased financial and technical support
by IBM beyond its original expectations. NCSA and IBM worked closely on
various proposals to retain IBM's participation in the project but could
not come to a mutually agreed-on plan concerning the path forward."
IBMはこれ以外には何も喋っていないので、以下は一介のIBM OB、素人の勝手な類推です。寝言です。
さて、関連するジャーナリストのコメントを見ると、IBMが技術的にギブアップしたわけではなく、お金の面で折り合いがつかなかったようです。
先進コンピュータ開発競争が、スピード(オンリー)とスマート訴求の2つの進路に乖離へ
小生は前のブログで、(スパコン”京”の世界一位の危うさ. スパコン開発の進路はスピードからスマートへ)、スパコン開発の進路がスピード競争からスマート競争に進路変更するだろう、と書きました。
その根拠の一つとして、オバマ大統領の科学技術アドバイザリーボードである PCAST(President’s Council of Advisors on Science and Technology)のTOP500スパコン・スピード競争への過度なのめり込みに対する警告をあげました。
この警告の背景にあるのは、現在のスパコンがスピード競争に奔走するあまり、新しいアプリケーション開発の大きな阻害要因になっている、という認識です。
過去に開発されたアプリケーシションやアルゴリズムをより速く処理することに夢中になって、新しいアイディアで未踏の分野に挑戦するようなアプリケーションの創り易さが無視されている、という警告です。
一方で、アプリケーション開発の難しさでまな板に上げられるのは、GPGPUや特殊目的の癖のあるプロセッサーですが、これはどちらか言えば既存アプリケーションに合いにくい、ポーティングが難しいという切口だけで論じられることが多く、現在進行中のスマート・プラネットやヘルスケアなどでの、センサーからリアルタイムで流れ続けるストリームデータの処理系などには殆ど関心が向けられていません。
このような、従来型算法を超えた未開の分野への挑戦を、スマート、と呼んでいます。
未開の分野は未だ十分にアーキテクチャなどが固まっていませんから、アプリケーション開発でも試行錯誤が多く、ソフトウェア開発の容易さ、変更などの容易さが重要な鍵となります。
その意味で、歴史があり、積み重ねられた技術のすそ野の広い汎用性のプラットフォームが出発点として重要になってきます。どこに、どのように向かうか未だ決めかねている冒険家のベースメント・キャンプですね。
今から経験を積んで行くのです。
さらに言えば、汎用性の決め手はデータシャリングにあると云えるでしょう。
伝統的なスパコンにしてもMap/Reduceなどにしても、予め良く設計され、貯めこまれたデータのパーティショノニングがスケーラブルの前提になります。パーティショニングは結構難しく、データの偏りや初期状態からの変異が大きいと極端にスケーラビリティが落ちてしまいます。
一方で、ストリーミングのような、データフローに演算が被っていくようなプログラミング・モデルでは、プログラムから見たデータシャリングが必須となるのでしょう。
Ddistributed Shared Memoryですね。
プラグイン的な多様なアルゴリズムが被り、ダイナミックに変わっていく途中データが関心事になります。
しかし、プロセス側の並列処理スピードアップはデータのローカリティが必須ですから、難しいテーマです。
一般に、コンピュータ・テクノロジーのチャレンジは、単位時間に送れるデータ容量を示すデータ転送バンド幅と、データ要求から実際に必要なデータが到達するまでのレイテンシー(遅延)のギャップ解消です。
これが伝統的なスパコンの応用領域では、データ密度や様々な工夫で乗り越えてきたわけですが、これからの応用分野がスマートを目指すとなると、仕掛けが戦艦巨砲的な構造では対応が難しくなるでしょう。
一般の処理形態が、バッチ処理からトランザクション処理に移行した時の課題に似ていると思われます。
その意味で、プログラミングの容易さを実現するために、汎用機のデータ一貫処理のDNAを持ちこみながら、それをスパコンのスピードに仕立て上げようとする技術の挑戦として、小生の頭の中では、Blue Waters はこの時代変化のマイルストーンとして、スピード競争を維持しながらもスマートさに大きく一歩を踏み出すスパコンだろうと期待していました。
ところがIBMはギブアップしてしまいました。正直驚きました。
しかし、小生は、それもありうるだろうな、と感じていて、前のブログでは次のように書きました。
「 Jack Dongarraさんによると、Blue Watersは現在、設計面で遅延が起こっているのだそうですが、この構想の壮大さからすると、さもありなんだと思います。
来年春のTOP500には間に合わないのかもしれません。」
IBMはこのBlue Watersを一般商用機にしたIBM Power 775を準備済みで、お客様リストも持っているらしいのですが、元の約束のように、NCSAが要求するTOP500スパコン・スピード競争に打って出て一位をとり、さらにZetaFlopsのスパコンに繋いでいくのは、コスト的にとても無理だと判断したのでしょう。
IBMにはBlueGene/Qという、スパコンのスピード競争を制してきた別のシリーズも持っていて、ローレンスリバモア国立研究所に導入される予定のSequoiaが20PFlops 、米国アルゴンヌ国立研究所に導入される予定のMira がその半分の10PFlops と、十分にスピード競争に参画はできます。
技術的にも、Blue Watersが手こずった斬新なインターコネクトではなく、従来から使っていたトーラスネットを今度は5次元で使うらしい。ちなみに京は6次元トーラスネットです。
その一方で、スパコンで始めて1Pflopsを突破したIBM Roadrunner で活躍したCellの開発を打ち切り、マイクロソフトの最新のゲーム機 XboxではGPUとPowerPC x3のSoCを開発しています。
何を言っているのかといえば、IBMはアクセラレータとしてGPGPUも真剣に考えているのだと思います。
GPGPUは、依然としてプログラミングが難しいと、一部では酷評されるアプローチです。
つまり、スピード競争とスマート競争を別のものとして、はっきりと割り切ってしまった、と考えられます。
Blue Watersの停止は一時的には名誉に傷がつくのでしょうが、そこはIBMはビジネスライクに決断したのでしょう。ある意味英断だと思います。
勿論、京の成功も、IBMの決断に大きな影響を与えたのは間違いないでしょう。
一方で、京は、汎用機のDNAとして、明らかにBlue Watersを仮想敵にしてきたと考えられます。
それが失せてしまった。世界のスピード競争の常識に挑戦する盟友を失ってしまった。
相手が降りたのだから勝ったといえます。しかし、勝った勝ったと大騒ぎをしているだけでいいのでしょうか。
GPGPUを小馬鹿にしても、Blue Watersの狙っていたスマートさの追求に比して、辛く言えば、京のアーキテクチャは伝統的なスパコンの延長線上にあり、GPGPUに対してDisruptiveな差別化は無いと思います。
極端に言えば、GPGPUの方がポーティングが面倒だ、ぐらいの違いでしょうか。
逆に、スピード・オンリー競争でのGPGPUという世界の大きな流れに打ち勝つことができるのでしょうか?
ExaFlops時代の100倍を超えるエネルギー効率の壁を乗り越えられるのかどうか。
インテル® MIC アーキテクチャーなども視界に入ってくるのでしょう。
では、京に、伝統的なスパコン応用を超えた、どのようなスマートさ訴求の戦略があるのでしょうか。
確かに京は素晴らしい伝統技術の成果ですが、それを大いに誇りにするも、驕りになっては大変危険です。
今までもこの驕りで日本の技術が坂の上から転げ落ちたことが何回もありました。
コンパイラや開発環境の、ソフトウェアの準備に追われているとは思いますが、それだけで良いのかどうか。
IBMは、IBM Watson という曖昧質問の解析マシーンが、Jeopardy という米国の人気クイズ番組で人間のチャンピオンに挑戦してこれを打ち負かし、賞金王になりました。
このマシーンは高々80 Teraflopsの浮動小数点演算性能しかなく、とてもTOP500のスパコン・ランキングにも登場しない商用機をハードウェアとして利用していますが、全米の大きな話題になりました。
IBM Watsonは、計算スピードでは遥かに劣るものの、コンピュータのインテリジェンスでは歴史的な能力を発揮したのです。これを全くジャンルの違う計算機系とみてよいのかどうか。
さらに、POWER8の市場投入が視野に入ってきましたが、今回のIBMの挙動で、その狙いがはっきりしてきたように思います。POWER8はよりスマートな世界創造へのアーキテクチャに大きく踏み出すのでしょう。
ですから、戦略は、スピード競争とスマート競争の違いを、しっかりと見つめ直さなければならないでしょう。
この場合、バランス思考ではダメで、ブレンド思考が必須です。
Blue Waters の何がスマートなのか.その技術の”簡単で勝手な”概略
もう技術の中身を論じてもあまり意味がありませんが、Blue Waters は大きなチャレンジをしていました。
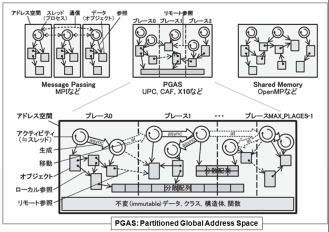
Ddistributed Shared Memory、Partitioned Global Address Spaceですね。
Blue Waters のアーキテクチャは、2002年から2010年までの間に3段階の競争を勝ち抜いた、PERCS (Productive, Easy-to-use, Reliable Computing System)をベースにしています。
PERCSは、DARPA (アメリカ国防総省の国防高等研究計画局)によるHPCS (High Productivity Computing Systems)という、スパコンのグランドチャレンジなRFPに対応して開発されました。
この設計の一貫で、汎用プロセッサーのPOWER7も開発され、特殊なハブ・スイッチで、プログラミングの容易さをスパコンに持ち込むためのアーキテクチャが構想されました。
特徴的なのは、データ分割の難しい応用分野にも挑戦できるグローバル・アドレス空間を用意し、並列処理ソフトウェア開発の容易さと、大容量データ処理能力にフォーカスしていることです。
並列処理における部分共有メモリー空間と、20PBに及ぶ外部永続データとの一体アーキテクチャです。
その意味では、データ分割を当然のこととして伝統的な浮動小数点演算処理を追求する、GPGPUや”京”のアプローチとは大きく違った設計思想で開発されています。データ中心の設計です。
このアーキテクチャを実現するために、Blue Watersは、InfinibandやIBMの独自設計のSysplexから発展したオープンのRDMA (Remote Data Memory Access)などを組み合わせた、プロセッサーが一対一直結の、新世代のインターコネクトを採用しているようです。これをStrong Scalingと呼ぶらしい。
IBMではPOWER4からマルチコアやチップ搭載メモリー・コントローラーなど、完全分散のプロセッサー結合を進めていましたが、基礎となる汎用のPOWER7では、256コア1対1直結が可能で、同時に20,000データ・ハンドリングのリオーダー整合性処理が可能なまで強化されています。巨大なスヌープの構造です。
PERCSでは4個のPOWER7に1個のハブチップが付いたモジュールを構成、メモリーをコア直結、系全体のクラスター、PCIe、ネットワークというインターコネクト全体はハブを通じて実行し、合計1128Gバイト/秒のピーク帯域幅を、各ノードやスーパーノード、汎用入出力タスクなどに振り分けるのだそうです。
これが、あの、バカデカくって、悪名高き”畳”の正体ですが、浮動小数点演算性能追求の”京”のTOFUのトーラスとは、データセンタを畳に集約したようなデータ処理系という点で、比較の対象にはなりません。
畳のプリント基板は日立が分担しているとのことです。
京が銅線接続に対して、Blue Watersは光接続です。
ソフトウェア・アドレス空間も、並列処理のプログラミングを容易にするPGAS(Partitioned Global Address Space)型のアーキテクチャで、新しくX10というJava拡張の並列型言語を開発、既にオープンソース化しています。この構造は、人間の脳の記憶モデルを参照しているという指摘もあります。
従来の単純な、データ分割のメッセージ交換型クラスター分散メモリーではありません。
一方で、京は左図でいう、伝統的なメッセージ交換型で、MPI対応しています。
我々日本IBMは、このRDMAの前身にあたる、データシェアの先進技術を始めて採用したメーンフレーム、Sysplexの世界最初の導入で、大変な苦労をしました。テストの工数が凄かったのです。
しかしRDMAは、IBMではすでに十分に経験された技術となり、同じPOWER7の超スケーラブル・システムの DB2 pureScaleは順調にお客様に受け入れられていると思います。
しかし、世界のスパコンのスピード競争に割り込み、より柔軟で粒度が圧倒的に細かい斬新なアーキテクチャとしての実績を積むのは、未だ、少し早いと判断したのだと推察します。
↑
|