IBMのHWの新たな挑戦.Blue Gene/Qで業界初のTransactional Memoryを導入
- IBM100周年のブロガーミーティングで大失敗.懺悔とフォローのためのコラム -3
2011年09月22日記述
Transactional Memoryは玄人好みのテーマで、一般にはなんのこっちゃ、という価値しか伝わらないと思いますが、これが一般解として利活用されるとなると、マイクロプロセッサーの風景が大きく変わる可能性があります。
かってSUNが果敢に挑戦しましたが失敗し、Oracleに買収される一つの原因になってしまいました。
技術の王道は先端分野への挑戦.IBMにみる社内複数チームの多彩な競争
IBMのビジネスモデルは脱HWだと度々論評されますが、内容的にはそんなことはなく、例えば最先端マイクロプロセッサーや半導体の開発力などでも、業界の覇者インテルを頻繁にリードする、数多くの発明や製品開発を行っています。コモディティ対イノベーションの図式ですね。
小生は一介のIBM OB、SEですが、IBMのサービスモデルはHWに大きく依存していると信じています。
そんなHWシンパの小生ですが、次世代スパコンBlue Gene/Qで業界初の Hardware Transactional Memoryを導入する、と、IBMがHOT Chips 23で発表したのを知って、正直驚きました。
これで次世代マイクロプロセッサーの技術動向が俄然面白くなってきました。
マイクロプロセッサーの話題になると、巷間ではIntel x86のコモディティ・チップの話ばっかりで、この業界はもうプロセッサーのイノベーションに関心はないのか、という苛立ちが募ります。
HPの元CEOフィオリナが、あろうことかAlpahやPA-RISCなど、かっての名誉あるマイクロプロセッサー(とその技術者)達ををガラクタのように捨て去り、自社の技術基盤をIntel Itaniumに絞り込むという暴挙を行ってから、独自技術の気運が大きく損なわれ、IT業界の技術景色は随分寂しい状況に陥っています。
さらに最近では、HPがPC部門などのHW部門を切ってSWやサービスにシフトする、とも噂されています。
これは、ソフトやサービス偏重の先輩ビジネスモデル、IBMになりたいのだな、などと論評されていますが、
zやPOWERというオリジナルなマイクロプロセッサーの開発に熱心なIBMにとっては迷惑な評論でしょう。
そのIBMも、パルミサーノがCEOになってからビジネスと技術のバランスが崩れがちになっていますが、今回のBlue Gene/Qの話題をみる限り、余り心配しなくてもいいのかもしれません。
IBMは、前のブログでも書きましたが、スパコンBlue WatersのNSC商談からのぎりぎりでの撤退で、技術の名誉をかなり傷つけてしまいました。投資コストに見合わないという理由でした。
来年には、20PetaFlopsというこのBlue Gene/Qを成功させて、不名誉を挽回するつもりなのでしょうか。
Blue Watersの世界最高速争いからの撤退決断も、代替策が選択可能な背景があったからなのでしょう。
(尤も、Blue Watersの一般商用機であるIBM Power775は引き合いが多いらしいですね。
なんでも、IBM WATSONの構成が80 Teraflopsで、IBM Power775のラック(96 TFLOPS)一つでカバーできるから、という理由だそうです)
IBMは世界一位を狙えるスパコンを3種類持っていました。
一つは、2004年秋/2005年/2006年/2007年とTOP500世界一位を獲得したBlue Geneですね。
最初のモデルBlue Gene/Lが、2004年秋、永らく世界に君臨していたNECの地球シミュレータを破りました。
地球シミュレータが5120プロセッサで 35.86TeraFLOPSだったのが、BlueGene/Lは1万6000プロセッサで36.01TeraFLOPSと僅差でしたが、世界の流れを変えたのが、物理サイズが1/100、電力消費が1/30という、PowerPC
440 x2 をHPC用にチューンしたASICを大量に使った、圧倒的な省エネルギーの技術でした。
今回、Blue Gene/QはPowerA2(Prism, 後述)のSoCになりましたが、16コアチップの消費電力は55Wで、ピーク演算性能は204.8GFlopsです。これを10万個並べて20PetaFlopsを出すらしい。
Blue Gene/QはGlueless(外部チップ無なし)で、チップ上に接続機構を全て実装しているため、水冷の外部トーラス構成チップを必要とする京に比べても大幅な省エネルギー化が期待されています。
省エネルギーが必須の、次世代ZetaFlopsスパコンの有力候補でもあります。
2つ目は2008年/2009年春でTOP500の一位を取ったRoadrunner。
Cell BE (PowerPC+SPE x8)とAMD(x86)のハイブリッドで、GPGPUスパコンの先駆けのアーキテクチャです。
初めて1PetaFlopsの壁を破りましたが、省エネルギーでも一位になりました。
3つ目がくだんのBlue Watersです。
10PetaFlops強を狙っていましたが、スパコン構成の全プロセッサーやI/O全てを統合する、Hubチップの強スケーラブル構造がネックになって、世界一位競争から脱落してしまいました。
256GFlops/チップのPOWER7を4個実装したモジュールとHubで、PERCS Building Block を構成します。
以上、3つのスパコンは全てPOWERアーキテクチャをベースにしていますガ、其々でユニークな構成アーキテクチャと技術を作りこみ、お互いに切磋琢磨してきました。
面白いことに、2004年前後で、IBMでは次世代プロセッサーの候補がC1(POWER7)、A1(Cell BE)、A2(Prism)の3種類がありましたが、この全てでスパコンに挑戦していることです。
このように、IBMには自社内に、ボトムアップ的な複数の競争者が存在し、其々が先駆的分野に侵攻することがよくあります。
極論すればファンドが確立していないアイディアが跋扈し、お互いの技術ディベートは日常です。
一方で、eDRAMのような共通の先進技術を共有して全体の開発コストを大幅に削減してもいます。
これが、次々とイノベーションを世に送り出せる、IBMの強みを支えている仕組みといえるでしょう。
かって、米IBMポケプシーLabが開発する水冷大型メーンフレームがダウンサイジングに直面して大失速した時、IBMを救ったのは独IBMボーブリンゲンLabが開発していたCMOSマイクロプロセッサーでした。
また、z SystemにLiuxの成功をもたらしたのも独IBMボーブリンゲンLabの若い技術者のボランティアでした。
同じようなことがIntelにもありました。
2004年、4GHz突破のPentium系Prescotの発表時点で、漏れ電力による熱暴走が発覚し、ムーアの法則を豪語していたIntelの大失態が顕在化しましたが、巧妙な戦略的転換を可能にし、その後のマルチコア化に素早く舵を切ることができたのはイスラエル・ハイファLabのcoreの存在でした。
経営が、トップダウン的なリーダーシップでフォーカスする戦略的技術を絞り込むのか、それとも現場の開発・研究者の自主的・ボトムアップに乗っかかるのか、は、企業のカラーを決める大きな選択です。
この点で、小生には面白い経験があります。
ソニーの久夛良木さんの歓送会のテーブルで、IBMの強みについて議論が及びました。
小生は持論の競争原理を述べますと、久夛良木さんはそれを言下に強く否定されました。
優れたものごとを具現化する力は、トップダウンのリーダーシップなのだ!、と。
小生は、複雑系の経営論で知られていた元ソニー会長の出井さんと、久夛良木さんのスタンスの違いに、思いをはせていました。
複雑系は、勿論、雨後のタケノコようなボトムアップの生成の、勝ち組に乗る、という思想です。
2006年頃から、ベンチャー研究者の開発を、M&Aで自社内に取り込むという経営モデルが一方で進んでいますが、自社内技術者への投資とモチベーションの活性化で、微妙な経営判断が要求されるでしょう。
Transactional Memoryとは
Transactional Memoryには、Softtware Transactional MemoryとHardware Transactional Memoryの2種類があります。ここでの論議はHardware Transactional Memoryです。
マイクロプロセッサーが処理対象とする一連の命令列のHWスレッドを、データベースのACID (Atomicity, Consistency, Isolation, and Durability) 属性を持ったトランザクションに似せてマクロ的に処理します。
マルチコア、マルチスレッド化の動向に沿った、将来の大容量処理プロセッサーのメモリー一貫性の方式設計として研究されています。
マルチコア、マルチスレッド化の進展で、従来のスケールアップ型SMP (Symmetric Multiprocessing)での並列処理(parallel
processing)、並行計算(Concurrency)の問題が一般化され、処理性能向上のためのより喫緊の課題として浮上しています。
逐次処理とそれを並列実行したときの結果が一致するためには、メモリーの一貫性が必須ですが、それをソフトウェア・プログラムから担保するためのHW実装命令として、メーンフレームやx86の
"compare and swap."命令や、PowerPC, MIPS, ARM, Alphaなどで使われるLL/SC (load-link / store-conditional)命令があります。
いわゆるロック命令ですが、これは潜在的デッドロックを内包したり、粒度が細かいために、プログラムからは扱いが大変困難で、一般のプログラマーの手に負えるものではありません。
これを、あたかもデータベース・プログラミングの乗りで容易に書けるのが、Transactional Memoryの第一のメリットとなります。
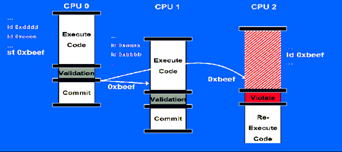
図1に示すように、複数のスレッドを平行して走らせ、スレッドが終わった時点で処理中に読み取ったデータが他のスレッドで更新されていなければ正常終了となります。
仮に更新されていれば、スレッドはアボートし、初めから再実行となります。
オプティミスティックな排他制御で、プログラムは一貫性制御をHW任せにし、大変楽になります。
問題は、これが理屈だけでなく、リアルワールドでうまく動くのか、です。 パーフォーマンスはどうなるのか。
Hardware Transactional Memoryへの挑戦はSUN ROCKが有名ですが、SUNは結局ROCKの開発に失敗して、Oracleに買収される一つのきっかけを作ってしまいました。
SUN ROCKの開発者によると、うまくいったケースもあるけれども、大半はうまくいかなかった、ということのようです。 どうも汎用マイクロプロセッサーとしては一般解を作れなかったようですね。
IBMなどでも前々から色々と研究はされていて、特に801 TM(例の世界初のRISCプロセッサーに似せた命名のようです)などという実装系で、効率や問題点を評価できる仕組みを持っているようです。
Transactional Memoryのブロックが小さいと、ハードウェア・スレッドの途中でオーバーフローしてしまいますし、逆に大きいと、他のスレッドによる更新の機会が頻発してアボートばかりで前に進めなくなります。
アプリケーションによってメモリー参照は千差万別となるのでしょうが、1Kから4Kぐらいが、適当なサイズだという話を聞いたことがありますが、詳細は知りません。
Blue Gene/Qの粒粒プロセッサー構成とTransactional Memory
Blue Gene/Qは勿論Hardware Transactional Memoryです。
SUN ROCKが失敗して以来、Hardware Transactional Memoryがいつ業界に商品として顕われるのか興味が尽きませんでしたが、結局、IBMが先陣を切ったわけですね。
Blue Gene/QはPowerA2(以下A2とも省略)のSoCになりました.
これはコードネームがPrismと呼ばれていたチップがベースで、Charles Johnsonが、2010 ISSCCで”Wire Speed Processors ”として紹介した、PowerEN(Power Edge of Network) と同じA2コア・ベースで構成されています。
彼はPOWER4マフィアのメンバーで、2010年のIBM Fellowにノミネートされました。評価されたのですね。
PowerA2の特徴は、何といってもThroughput Computing指向のプロセッサーだということです。
A2コアは、Power v2.05 標準バイナリー互換の汎用プロセッサーですが、2命令発行、out of order無しのシンプルなコアになっています。
小生はこれを粒粒プロセッサーと呼んできました。
小さなプロセッサー・コアで、大量スレッドを低電力・低発熱でさばきます。
これと同じというか、同時期に一歩早く業界に鮮烈なデビューを果たしたのがSUN T1 (Naiagara)です。
CMP(Chip MultiThreading)によるThroughput Computing ですね。
この両者は思想的には同じものです。
T1 (Naiagara)は、メモリー一貫性制御に弱く、結局Javaなど一般アプリケーションでは性能を出せず、泣かず飛ばずで終わってしまいましたが、PowerA2にも本来同じことがいえます。
このてのプロセッサーは、かってはNetwork Processorという範疇で存在し、IBMでもPowerNPという商品ブランドがありましたが、 確か2002頃、PowerNP と PowerPC を統合してしまい、PowerNPのIPは売り払ってしまったと思います。
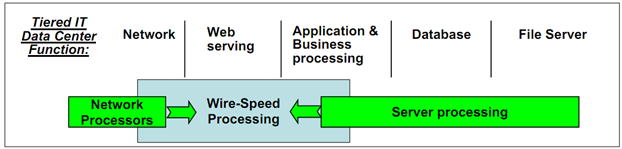
IBMはSUNの失敗を横目で見ながら、先祖がえりする形で、Wire Speed Processors(図2参照)、としてデビューさせたわけです。
スマーター・プラネット時代のストリーム処理、ICT(情報通信融合)のコア・プロセッサーの位置づけです。
なかなかの知恵者といえます。
小生の興味は、Blue Gene/Qで、IBMがこのPowerA2にTransactional Memoryを実装した、という点にあります。一過性なのかどうか、興味が尽きません。
(下に続きます) |