|
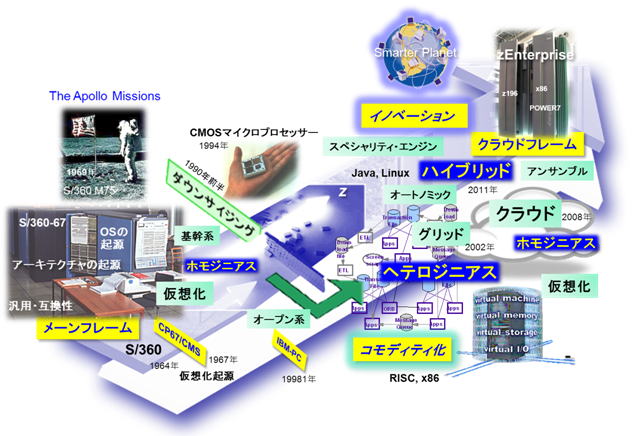
クラウドフレームの言葉の背景.zEnterpriseをメーンフレームの言葉だけでは説明できない
”クラウドフレーム”は小生が創った新しいバズワードです。
ブロガーミーティングに招待され、メーンフレームの説明とその未来動向をブロガーの皆様と共有するために、新しいキーワードとして創作しました。
商標なども関係なく、海外でも同じ文脈では一切使われていないようですので、新しい言葉です。
といっても、全くのデタラメな言葉ではありません。多くの識者に打診しましたが、納得・支持頂いています。
日本IBMのキーマンとなるエバンジリストの方も、一部で既に利用し始めていると理解しています。
IBM zEnterpriseの構造は、後述しますように、アンサンブル技術(後述)がベースにあって、IBM CC-RA(Cloud Computing - Reference Architecture)に準拠しています。
ということは、IBM zEnterpriseは既に、(IBM)技術的にはクラウド対応になっているということです。
一方で、IBM CC-RA準拠の製品群には、CloudBurstなど、既に多くが発表されていますが、 zEnterpriseをクラウドだとは、IBMは、いまのところ、積極的にラベル化、ブランド化していません。
背景として、米IBMは自社のメーンフレーム・ブランドに十分自信を持っており、逆に、クラウドに対して企業IT部門が持つネガティブな感情に配慮しているのだと考えられます。
この当たりの風景を、以前のブログ、”IT業界の風は乱気流? 雲の流れ、クラウドはどこへ向かうのか”、で書きました。
しかし、日本では国産メーンフレームの存在感が世界に較べて遥かに大きく、しかも、日本ガートナーの亦賀忠明さんが度々指摘されるように、その国産メーンフレームの内容が古色蒼然で、IBMメーンフレームとの内容の乖離が大変大きくなっています。全く違うもの、といっても言い過ぎではありません。
さらに日経コンピュータが2010年10月27日号で「オープンメインフレーム」の言葉の定義を恣意的に変えてしまったために、メーンフレームという言葉が何を意味するのか、誰にもきちんと説明できなくなっています。
そんな背景もあって、日本IBMがIBMメーンフレームを説明する上で困惑し、ブランド戦略上、”メーンフレーム”という言葉の扱いに大きな苛立ちと不満を持っているのが事実です。
そこで、日本IBM某幹部が、”メーンフレームと呼ばずにハイエンドサーバーと呼んで欲しい”とか言い出して、失笑を浴びてしまったり、散々です。
以前のブログ、”IBMがメーンフレームを止めるって本当ですか?”、で、小生もその辺の事情を皮肉ってみました。
IBM zEnterpriseはそのフレーム(筐体)に、System zのみならず、Powerブレード/PowerVM上のAIX群やx86ブレード/KVM上のLinuxおよびWindows群、さらにはビッグデータ処理等も含む多様なアクセラレータを内包したハイブリッド構成となっており、それらがクラウド相当の管理系で統合されています。
図10を参照
ここでの結論は、”メーンフレーム”のカテゴリーでは、IBM zEnterpriseを説明できない、です。
(補)メーンフレームとオープン系との思想的な違い.エラー検出と隔離性のアーキテクチャ
少し技術的な解説になりますので、論旨展開上、次に読み飛ばしていただいて結構です。
但し、資源共有の効果を発揮するクラウド環境では、この検出と隔離の機能は大きな論点になります。
日経コンピュータは、ハードウェアやソフトウェア・スタックを垂直統合しただけのモデルをメーンフレームと断じ、そのスタックにオープン系の素材を配したものをオープンメインフレーム、と定義してしまいました。
同誌がそんなことを言い出すまでは、”オープンメインフレーム”はIBM用語で、あくまでメーンフレームの定義ともいえる以下の信頼性のキーワードが前提の上での、オープン化対応でした。
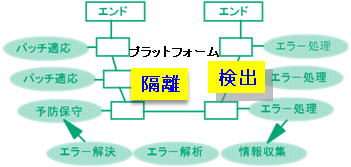
メーンフレームの本質的なアーキテクチャ上の特徴は、本来、FFDC(First Failure Data Capture)に代表される、潜在エラーを見逃さないエラー検出の厳格さと、それに基づく各レベルでの隔離能力にあります。
アプリケーションがプラットフォームを信頼して、業務構築に専念出来る仕組みがメーンフレームです。
図4
一方で、図5に示すように、オープン系の思想は、この面でのアーキテクチャ・コストにネガティブで、good enough という思想性のもと、プラットフォームはマクロな対応しかしません。そこにコストをかけない。
例えばメーンフレームのアーキテクチャを特徴づけている構造の一つに、I/O系処理をチャネルという独立した処理系に分離・分散した思想があります。
このチャネルの構造により、信頼性に大きな凹凸のある多様であなた任せな外部デバイスを、高信頼系のプロセッサーに繋ぎ込めるのです。
オープン系システムでの大きな脆弱性の一つに、カーネルモードで走るデバイスドライバーなどの暴走がありますが、これなどはメーンフレームでは絶対起こりようがありません。
これに関連したアーキテクチャ上の大変重要な機能として、メーンフレームではデータ・エリアに個別の記憶保護キーを設定出来ることがあげられます
特権モードの下で多様なプログラムがデータ・エリアを共有することになりますが、本来許されていないプログラムが他人のデータ・エリアを書き換えてしまい、時間が過ぎた時点で本来のプログラムがその書き換えられしまっているデータに遭遇してエラーを起こすことがよくあります。
プラットフォーム系ソフトウェアにおける信頼性の最大の課題です。
メーンフレームではプログラムとデータ・エリアの関係を厳密に規定出来ることによって、隔離されます。
クラドではマルチテナントなど共有・共用環境でのセキュリティ隔離が大きな課題になりますが、これなどはメーンフレムの生い立ちである汎用コンピュータの基礎技術として基からアーキテクトされているわけです。
このようにメーンフレーム系とオープン系ではエラー検出と隔離の思想が大きく違うため、
可用性 (High Availability)においても対応が異なります。
メーンフレーム系ではエラーの原因解明と解決が可用性と一義ですが、オープン系では素早いリブートなど、系の再立ち上げ時間の短縮が最大の関心事になります。
少々乱暴に言えば、ソフトウェア・バグなどのインテグリティ・エラーの遠因が保持されたまま走り続けます。
IBMメーンフレームがオープン系の素材を積極的に組み込めているのは、基本にある厳格な検出と隔離の構造が備わっているからです。これを見失うと、ITのアーキテクチャを論じることが出来なくなります。
(オープン系のIBM p SystemにおいてはFFDCに対応し、POWER6からは記憶保護機能が実装されています)
論旨に戻ります。
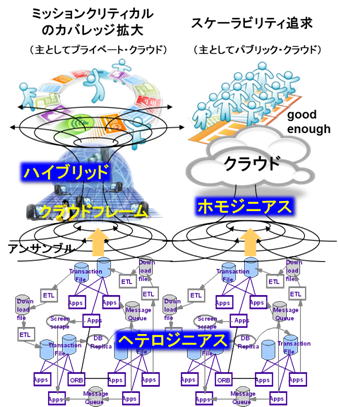
クラウドフレームは、クラウドのミッションクリテルカル・カバレッジ拡大の受け皿
小生は、クラウドフレームという言葉を、単にIBM zEnterpriseを説明するためだけの目的で創作したわけではありません。
今のところ、クラウドフレームの名前に値する商品はIBM zEnterpriseしか存在しないのは確かですが、
クラウドの浸透とともに、企業アプリケーションのミッションクリティカル要件への対応拡充が、企業がクラウドに求める、新時代の重要なプラットフォーム要件になっていくのは確かだと考え、創作しました。
この要件を満たす商品カテゴリーを、”クラウドフレーム”という新しい用語で表現したい、と考えたわけです。
メーンフレームが伝統的にミッションクリティカル・プラットフォームとして頑張ってきたわけですが、その思想、律義さをDNAとして受け継ぐ、クラウド時代の多様なアプリケーションの受け皿、フレームです。
ここでいうミッションクリティカル要件とは、セキュリティも当然含む、様々なNFR(Non Functional Requirement)の充足を意味しています。
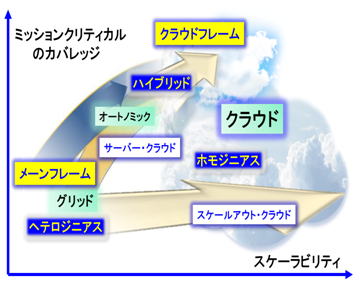
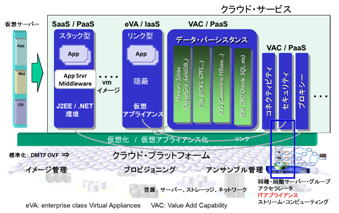
クラウド環境の、ミッションクリティカル・カバレッジの拡がりのイメージを図1(再掲)に示します。
クラウドのミッションクリテルカル・カバレッジ拡大と、敷居の低い安定した受け皿は必然
クラウドがグローバル・サイズのスケーラビリティを指向するのは本質的ですが、一方で、クラウドによるグローバル化の進展とともに、今までの常識の範囲を超えた多様なアプリケーションが、よりシビアなミッションクリテイカル要件を必要とするようになって行くとのは必至だと考えられます。
今までのローカルに閉じた企業アプリケーションでは、仮にトラブルが起こっても、ある程度、身内意識で済ますことが出来るので、多くのアプリケーションの信頼性は、相応のレベルで済んだのだと思います。
ダウンサイジング以来のオープン系のキーワード、good enough のスタンスですね。
しかし企業活動がグローバル化するにつれ、国の法律や慣例が多様化し、民族の重なりが複雑になれば、小さな間違いや例外処理の誤謬が、大きな命取りに繋がってしまうリスクが拡がります。
グローバルな環境では、全てのアプリケーションが、GRC (Governance, Risk, Compliance)やBCP (Business Continuity Program)の対象になってくるのでしょう。
勿論、、プラットフォームの RAS, RASIS(Reliability Availability Serviceability Integrity Security)のレベルも、good enoughでいいんだ、などと呑気に構えていられなくなるでしょう。
これが出来ないからクラウドはやらない、というのは一つの識見ですが、クラウド化は進展するでしょう。
そこで、クラウドの新しい要件として、容易なミッションクリテルカル・カバレッジ拡大が重要になってきます。
企業部門システムに広く適用されたクライアント・サーバー構成技術と同じのりで、Webの世界でも全てのIT素材はgood enoughでOKなのだ、という多くのIT技術者の今までの常識が覆ることになるでしょう。
何故なら、後述するように、good enoughの素材でも工夫すれば ミッションクリテルカルは構成することができますが、一時はやったBASE理論(Basically Available, Soft state, Eventually consistent)の主張が示すように、多くの場合、現行の一般的なIT技術を超えた、超玄人の統合技術が要求されます。敷居は大変高い。
そこで、RAS,RASISなどは古い言葉で、IBMがメーンフレーム全盛時代に作った言葉ですが、伝統的に厳格なミッションクリティカル要件を満たすメーンフレム系技術としてクローズアップされることになります。
クラウド時代になって、ダウンサイジング以前のメーンフレームにそのまま回帰することはとても考えられませんが、今でも多くの企業の基幹システムがメーンフレームに大きく依存している現実を直視すれば、素直にメーンフレーム系技術を学ぶ態度がIT業界では必須になると考えられます。
メーンフレームと聞くと、はなから聞く耳を持たない最近の若い技術者の真摯に技術に向き合わない偏見が、自分の可能性を自分で壊してしまう愚を犯すことになり、将来、悔やむことになるのかもしれません。
これと似た風景が、インターネット・バブルが弾けた2000年の初期にも、 IT業界に見られました。
その時は、インターネットの浸透とともに顕在化したWeb系システムの脆弱性を克服するために、システム管理の重要性が再認識され、メーンフレーム系技術の応用が意図されたことがありました。
インターネット・バブルが弾けたのは、システム管理の稚拙さが一つの原因
2000年にインターネット・バブルが弾けた原因の一つにWeb系システムへの過剰投資の破綻があります。
1990年代後半、インターネットの成功に呼応して、Webトラフィックが暴発していきましたが、一方で、当時のWeb系システムは、システム効率・管理技術が未だ未成熟なオープン系サーバーで構成されていました。
そのため、ピークやスパイクの処理に動的に対応できず、システムダウンを頻繁に起こしていました。
そこで、これに対応する処理能力や信頼性向上を、単純にサーバー台数の数を増やすという行き当たりばったりで柔軟性のない方法で、スパイクに合わせた資源手配の対応を試みました。
結果として、インターネット系企業では、実収入が無いままに、サーバー投資が経済効率を無視したバブル状態にまで膨れ上がり、一気に破裂してしまったのです。
これに先立つ1990年・年央から始まった企業システムのダウンサイジングの是非について、IT業界での多くの議論がメーンフレームとオープン系サーバーのコスト構造の違いに費やされました。
TCO (Total Cost of Ownership)、すなわち運用を含めたコストとAquisition cost のボトムラインの比較です。
結局この論戦は、IT部門の結論というよりも、投資のスポンサーである現業部門の強い要請のもと、調達コストが安いオープン系サーバーへの流れとして決着しました。
しかしIT技術的には、IT資源の効率的な管理や信頼性の確立などが置き去りにされ、メーンフレームで確立されていたミッションクリティカル・システムの方法が、ウザイ考え方として蔑ろにされる風潮になりました。
この流れを常識として、インターネットのWeb系システムではオープン系サーバーが100%の常識として採用され、新しく勃興する初期のWeb系システムがコンテンツ中心に展開されたこともあって、トランサクション処理に偏在したメーンフレーム系は全く無視された形で技術が展開されていきました。
結果として、インターネット・バブルが弾け、多くのベンチャでは大きな代償を払う羽目になりました。
ヘテロジニアスの極めて複雑なシステム管理の課題に、グリッド・コンピューティンで挑戦
インターネット・バブルを何とか乗り越えた企業においては、Web系システムへの過剰投資を解決するための方策として、Web系システムでのシステム管理能力の実現を、強く望みました。
また、後にeビジネスとして開花するインターネットでのトランザクション処理は、ミッションクリティカル要件を満たすことが必須の条件になります。
このようなユーザー・ニーズを受けて、IBMでは、Linux on z で奔走したJeff NickがIBM Fellowに推戴され、Sysplexの開発時から続いていたユーザー企業とのアーキテクチャ設計会議であるCDC (Customer Design Council)の議長として、またメーカーの責任として、オープン系システム管理の強化に踏み出します。
2001年4月のIBM eLizaイニシアチブの発表です。
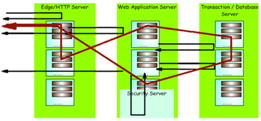
当時の企業系のWeb系システムは、図6に示すような、Webサーバー、アプリケーション・サーバー、DBなどのバックエンド・サーバーの複合ティアから構成され、さらに其々が大規模な台数、且つメーカー混在のWindows, Unix, メーンフレームなどで構成される、典型的な、ヘテロジニアスな環境にありました。
そして、このような複雑な環境の管理ツールが無かったために、全体を統合した、end to end のトランザクション・レスポンス管理や全体の整合性確立が大変困難でした。図6
某インターネット系証券のサービスなどでは、お得意様トランザクションと一般のデイトレーダーのそれとの間でサービスに優先順位がつけられず、お得意様のサービスレベルを維持するために膨大なサーバー投資が必要になり、苦しんでいました。
eLizaイニシアチブはこのようなヘテロ環境全体に、メーンフレームと同等のシステム管理能力を付与しようという、破天荒な挑戦でした。
この管理系を、IBMではオートノミック・コンピューティングと呼んでいました。
具体的には、Jeff Nickはグリッド・コンピューティングのIan Foster と組んで、2002年のOGSA(Open Grid Services Architecture)の発表へとこぎ着けます。
ヘテロな環境では、先ず、メーカーに囚われないオープンな仕様が必須だったわけです。
しかし、このグリッド・コンピューティングは、JEFF NICKがSOAを引っ張るDon Fergusonとのアーキテクチャ論争に破れてIBMを去るにいたって、急速に勢いを失い、実現できませんでした。
結果として、マルチベンダーで構成されるヘテロジニアスな環境のシステム管理が如何に困難であるか、という教訓が残りました。
しかし企業システムがヘテロであることの本質は、機器の調達や個々のライフサイクルを考えると避けられない命題であり、それがIT業界にとっての大きな課題として解決されずに残りました。
結局ヘテロな管理が挫折.Googleはホモジニアスで成功.サーバー・クラウドは仮想化へ
グリッド・コンピューティングの実質的な失敗という、IT業界の閉塞感を打ち破ったのがGoogleです。
2006年8月9日、GoogleのCEO(当時)Eric Schmidtが、世界規模のサーチエンジンとそのビジネスの大成功を背景に、新しくクラウド・コンピューティングというバズワードを発信しました。
クラウド時代の幕開けです。
Googleの成功は、
・ Intel x86チップを素材に、グーグル自身のカスタムメイド・サーバーの独自・単一インフラストラクチャ
・ Bigtable をGFS (Google File System)に展開し、データ・リプリケーションによる独自のRAS技術構築
・ MapReduceでデータを自動的に並列化し、安価なマシンの大規模クラスタで実行するNoSQL(KVS)創作
にあると考えられます。
簡単に言えば、自社システムを超単一仕様、即ちホモジニアスな環境に組み上げることによって複雑さの暴発を抑え、数十万台に及ぶ膨大なサーバー群で構成されるシステムの構築・運用に成功したわけです。
メーンフレームがメーカー固有技術のホモジニアスの典型ですが、Googleは膨大な数のオープン系サーバーを相手に、ヘテロからホモへの転換を図り、成功させたわけです。
驚愕ですね。
このオープン系、さらに言えばコモディティなx86サーバーを素材とするホモジニアス化は、Web系システムの常識となりますが、その構成・管理技術はGoogleやAmazonなど、個々のWeb系サイトで違います。
自社技術でホモジニアスに仕上げるわけですから、異なるのは当然ともいえます。
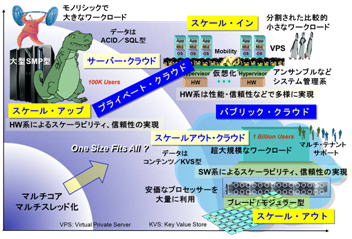
そして、Googleがクラウド宣言を発してから、グローバルなWeb系大手は一斉に自分自身もクラウドと主張し始めますが、内在する技術の違いをフォレスター・リサチは、Google系をスケールアウト・クラウド、Sales.forceやAmazon.com系をサーバー・クラウドと区別しました。図7
(サーバー・クラウドとスケールアウト・クラウドは別物)
特にSales.forceは元来ASPとして、SUNのSMPサーバーとOracle DBの一般的な構成で出発しています。
その後、コモディティなx86サーバー群を素材とするホモジニアス化に踏み切っていますが、Google以外のサーバー・クラウドの共通したアプローチは、x86系サーバーの仮想化にあります。
x86のホモジニアスなクラウドだけでは、ミッションクリティカル・カバレッジの拡充は無理
さて、スケールアウト・クラウドの雄Googleを始め、仮想化をベースにしたAmazon、Salesforce、MS Azule、VMware
などの全てが、大量のホモジニアスなx86サーバーを駆使してクラウドを構成しています。
そして、これらのクラウドは其々の技術力により、クラウドが管理する膨大な資源を簡単に利用出来るクラウド・サービスの形で、ユーザー・アプリケーション構築をを可能にしています。
IaaS、PaaS、SaaS などの仕組みです。
論点は、これらのクラウド・サービスの、提供されるミッションクリティカル・レベルの程度です。
GoogleやAmazonの本来の自社システムがミッションクリティカルであるのは当然ですが、x86サーバーという、オープン系サーバー群の上に構築される、多様なアプリケーションのミッションクリティカルの程度はどのようになるのでしょうか。
x86サーバーは、マルチコア化の成功による性能向上と共に、Itaniumとの差別化のために永らく導入してこなかった信頼性の拡充にも対応し始め、進歩しているのは確かでしょう。
多くの企業で、基幹系システムにも、x86サーバーが導入の対象になってきているのは事実です。
しかし、クラウド環境ではどうでしょうか。
クラウド環境における、クラウド・サービス実装の素材としてのx86サーバー及びそのソフトウェア・スタックに対する要件と、一般企業系システムで使用するx86サーバーでの要件は、やはり大きく違います。
手元に置いて当事者能力を発揮できるオンプレミス環境と、クラウドに任せきる全自動運用に近いオフプレミスでは、素材の能力が同じでも、実際の運用やその結果が違ってくるのは当然です。
さらに、クラウドにおいては、他社・他者との資源の共有・共用が前提となりますから、占有仕様での非機能要件に比べて、遥かに高いレベルの非機能要件が必要となります。
素材は同じなのですから、その差を埋めるのが、クラウド事業者の技術となります。
クラウドの本質はスケーラビリティの訴求ですが、それを実現する上で、BASE理論は、諸々のエラーや例外処理を利用者側アプリケーションでさばく、自責の設計・構造が必須だと主張しています。
このような構造が前提となる限り、ミッションクリティカル・カバレッジの拡充は簡単にはいかないでしょう。
プラットフォームのエラー対応までもアプリケーションでカバーするのは大きな重荷になります。
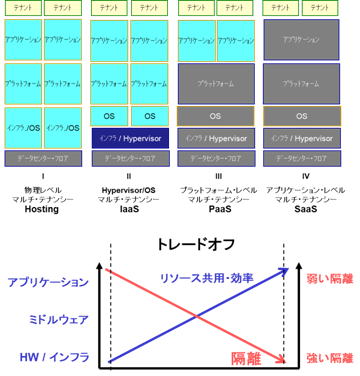
さらにクラウド環境では、共用資源の有効利用と、テナント間のデータやエラー、セキュリティなどの相互干渉を防ぐ、隔離の仕組みの頑健さ、とのトレードオフが大変重要になります。図8
(マルチ・テナンシー構築の方法と考慮点)
マルチテナント実現方法選択の重要な議論ですね。
図4,5を使った補足説明の項で論じたように、x86などのオープン系素材のエラー検出や隔離の実装は未成熟で、粒度の粗い対応しか出来ません。HW基盤やOS系のプラットフォーム素材としての脆弱さです。
これを、図3で示すようなレイヤー上層部の仕組みで、個々のシチュエーションに応じて補うのがクラウド提供者の技術となるわけです。
ところが原理的に、他者との共有の程度が拡がるため、上層での対応に頼れば頼るほど、隔離性が脆弱になります。
小生は、x86サーバーをホモジニアスに配するクラウド技術は、この面で未だ答えを得ていないと考えます。
いずれにしても、私たちは今回の東北大震災や福島原発の大事故を通じて、想定外という言葉の恐ろしさを肝に銘じたわけですが、クラウド環境においても想定外への対応の仕組みが必須です。
この場合、早期の異常事態の正確な検出と、各ユーザー側の確実な隔離の仕組みが重要になります。
この観点で、企業内ではあるものの、多様なアプリケーションのミッションクリティカル・カバレッジを達成してきたメーンフレーム・アーキテクチャの実績を看過するのは、賢い対応とは言えないでしょう。
企業系はヘテロからハイブリッドへ.さらにクラウド技術で統合するクラウドフレームへ
このメッセージを発信することは、小生個人にとって、少々の思想的転向を意味することになります。
このラマンチャ通信、特にeCloud研究会のテーマが、クラウドの先進性を生かした、新しい時代の企業システム、エンタープライズ・システム構築を、アーキテクチャ面から支援していく事でした。
閉塞感漂う日本ITに技術の新しい風を吹きこみ、再び世界をリードする日本企業のための、IT再構築です
視界にあった技術は、一般的なクラウドの技術です。
ところがこのブログの主張は、クラウドフレームの提言です。
そして、クラウドフレームに比定できる実体は、今のところ、IBM zEnterpriseしかありません。
つまり、グローバル時代の企業革新をIBM zEnterpriseでやろう!ということです。
転向のきっかけは、ブロガー・ミーティングでのIBM OBとしての意識の高揚です。
さらに、本気になったのは、小生が2年以上主張してきた、
”プライベート・クラウドを念頭に置いた、ユーザー主導のアーキテクチャ創立”の提案が、全く進展をみせなかったことに原因があります。
出来るだけ、メーカの素材を超えたところにグランドデザインの理想を置く、ことをモットーとしてきましたが、やはり無理でした。
結局、メーカーが製品として姿を具体的に表現しない限り、日本では誰もイメージやビジョン創りをスタートさせることが出来ない、という現実に、挫折したわけです。
しかし小生の技術的な主張は全く変わっていません。小生のアイディアのベースもIBM CC-RAにあったので、当たり前といえば当たり前です。
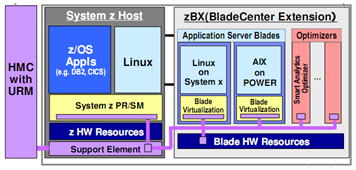
2年以上展開してきたアーキテクチャ論の集約を図9に示しますが、これを具体的に製品化したものの一つがzEnterpriseでもあります。図10がその構成です。
(ユーザー企業主導クラウド・アーキテクチャの概要)
図9、図10で共通するキーワードが、アンサンブル管理とvmイメージ、仮想アプライアンスです。
vmイメージや仮想アプライアンスの詳細は、eCloud研究会のレポートに詳述しています。
これからは、zEnterpriseを一つの具体的な雛形として、クラウドフレームを論じていきたい、と思います。
逆に言えば、eCloud研究会で展開したユーザー主導のアーキテクチャ論も、より具体的に議論することが出来ると思います。特に企業のチェンジ&レジリエンスで主張したアプリケーションの積極的なバージョニングは、是非実現したいと思います。
また、他にもこのブログで主張した、ミッションクリティカル・カバレッジの拡充を目指す商品が出て、
クラウドフレームというジャンルが確かなものとなれば、日本のITも変われるのでは、と考えてもいます。
例えばIBMで言えば、往年の名機と呼ばれる、AS/400, System i をカバーする、クラウドフレームを期待したいですね。
前々から、 System i をクラウド環境で具現化することを日本IBMに提言してきましたが、 過去にSystem i にはx86 Windowsとのハイブリッドな製品もあり、それがzEnterpriseのアイディアの原点でもあったと思います。
Power環境のアンサンブルが存在するわけですから、クラウドフレームとしての製品化は容易でしょう。
いずれにしても、企業システム環境が、ホモジニアスなものに統一出来るとは考えられません。
グローバル化の流れを一歩も二歩も日本企業が先取りしていくためには、ITのヘテロな環境を上手にクラウド化して、一刻も早く世界で活躍することが必要です。
中国などは、これまでも中国工商銀行の例に見られるように、System z の世界最大級の構成でITの先陣を切っています。メーンフレームがどうのこうのという偏見に、全く囚われていません。
そしてここにきて、このブログの冒頭で示した"Smarter Citizens" Cloud の発進がありました。
以下はIBMのアプローチについて見ることにします。 少し製品寄りの解説になります。
IBM OBの大雑把な解説としてお受け取りください。
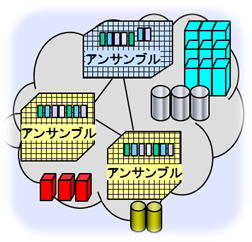
さて、IBMは、グリッド・コンピューティングの失敗で、ヘテロ環境の統合の困難さを嫌というほど実感したわけですが、それにはめげず、逆に学習した結果、標準化によるマルチベンダー環境のフラットな構造の統合を諦め、それぞれのアーキテクチャーごとに、仮想化を前提としたリソース・プールにまとめ、自律的に最適な状態を保つような管理の仕組みを考えだしました。それがアンサンブルです。図11
アンサンブルは2つの重要な役割を果たします。
①アンサンブル内部を高度に自律管理する事
②外に対しては非常に単純化された資源として単一システムのように見せる事
IBMはアンサンブルをローカル・アンサンブルとグローバル・アンサンブルの2つのカテゴリーに分けて、上手に分散管理を実現しています。
アンサンブルは資源グループごとに構成され、 サーバー・アンサンブル、 ストレージ・アンサンブル、 ネットワーク・アンサンブル、の3種類があります。
zEnterpriseのアンサンブル管理はURM (Unified Resource Manager)が一元管理し、1つのグローバル・アンサンブルになっています。その下のローカル・アンサンブルとしては以下のものがあるそうです。
・z/VM上のz/Linux群(under VMのz/OS,z/VSEを含む)
・zBX内のPowerブレード/PowerVM上のAIX群
・zBX内のx86ブレード/KVM上のLinuxおよびWindows群
・z/OSなどが動くLPAR (LPARについてはアンサンブル機能は現時点で一部制限があり)
アンサンブル管理の対象はあくまで仮想化が前提で、仮想アプライアンスの単位となります。
アンサンブルの外部インターフェースも提供されています。 (UI, CLI, REST経由のAPI)
IBM zEnterpriseではこのクラウド系管理システム体系のコアを、工場出荷のFirmware化で徹底して隠ぺいしています。HWに入れ込んでいるのです。徹底してハッカーなどの、外部や内部のアクセスが出来なくなっています。
↑ |